Finding Similar Items (1)- Overall
在一般低維度的資料中,找尋相似的資料只需要透過線性搜尋(linear search)以 的時間複雜度去搜尋即可,像在二維的空間中找尋相近的點等。但若對高維度、資料量大的資料進行線性搜尋就會花上過多的時間,而在現今有非常多這類型的應用。
如:
- 圖片檢索(以圖搜圖)
- 對相似主題的網頁分類
- 尋找抄襲、重複的文章內容
為了解決時間複雜度的問題,我們不要求找到最接近的資料,犧牲掉極小部分的正確性,並採用 Hashing 的技術來加速,以達到 的時間複雜度。
為了達到加速,基本上就是針對高維度、資料量大這兩個特性來做處理。
-
高維度: 一張1000*1000的照片,若不對他做任何處理,他的維度高達1,000,000,因此我們希望找出能保留相似度但維度較小的特徵 (signatures),以達到降維的效果。在這邊使用能達到此特性的降維技術的是Min-Hash。
-
資料量大: 若今天在資料庫中 N=10,000,000,即使解決了維度高的問題,時間複雜度仍是 ,只要N的值很大,仍然需要花上許多計算時間。若今天我們能透過一個hash函數,讓原本相鄰的點有高機率被映射到同一個bucket中,而相距較遠的點不容易被分到同一個bucket。有了上述的特性,由於相似的點已經被分到同一個bucket內了,我們只需要對同一個bucket內的資料 (Candidate pairs) 做線性搜尋就好了。如此將N分為了很多個子集合(bucket),針對子集合內的資料作線性搜尋,就能達到接近 的效果,而這邊利用到的技術則是LSH(Locality-Sensitive Hashing)
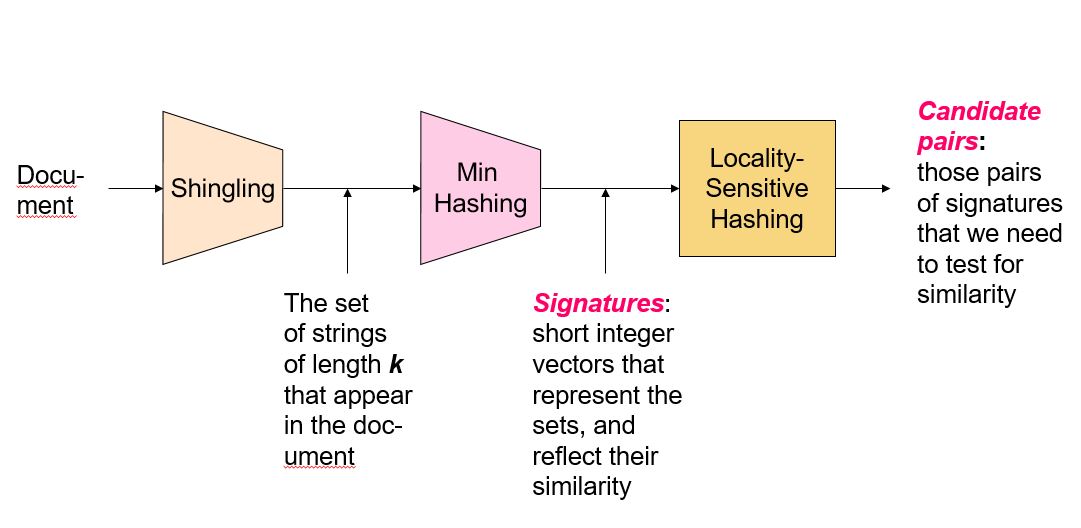 (image source: MDA course slides in NTHU)
(image source: MDA course slides in NTHU)

